Représentation des caractères#
La représentation des textes dans un ordinateur s’appuie sur un encodage. Une table associe un nombre à chaque caractère. Les systèmes d’exploitation possèdent ces tables et font la conversion en binaire.
L’informatique créée aux Etats-Unis, a pu se contenter 128 caractères en anglais pendant longtemps, mais ces caractères sont devenus insuffisants notamment avec les langues latines et leurs nombreux caractères accentués. Les tables se sont alors agrandies et se sont harmonisées.
Mais d’autres langues, comme l’arabe, le corréen et le japonais qui utilisent des caractères très particuliers, propres à leurs langues, ont conduit à étendre encore les tables de caractères.
On peut retenir 3 tables de codage importantes :
La table de codage ASCII créé dans les années 1960.
La norme ISO 8859-1 et 8859-15
Le codage unicode et sa représentation en UTF-8
Le codage ASCII#
La table de caratères ASCII (American Standard Code for Information Interchange) a été élaborée au début des années 1960.
Cette norme définit un jeu de 128 caractères représenté par un octet, mais seuls 7 bits sont utilisés d’où le nombre de caractères utilisés puisque sur 7 bits on dispose de \(2^{7}=128\) valeurs différentes.
A chaque codage binaire d’un caractère est associé un nombre décimal égal à cette valeur binaire convertie.
Exemple
Voici quelques caractères de la table ASCII:
Le caractère
A, en majuscule, correspond au nombre décimal \(65_{10}\) dans la table ASCII que l’on note \(41_{16}\) en hexadécimal et de codage binaire \(01000001_{2}\).Le caractère
a, en minuscule, correspond au nombre décimal \(97_{10}\) dans la table ASCII que l’on note \(61_{16}\) en hexadécimal et de codage binaire \(01100001_{2}\).
Indication
La table ASCII contient des caractères spéciaux entre \(00\) et \(32\) comme les caractères blancs (espace, tabulation, etc), retours à la ligne, suppressions et des caractères de contrôle. Ce sont des caractères non imprimables.
A ces 32 caractères spéciaux, il y en a un dernier de valeur décimale \(127_{10}\) qui correspond à la touche del du clavier.
Table de caractères ASCII
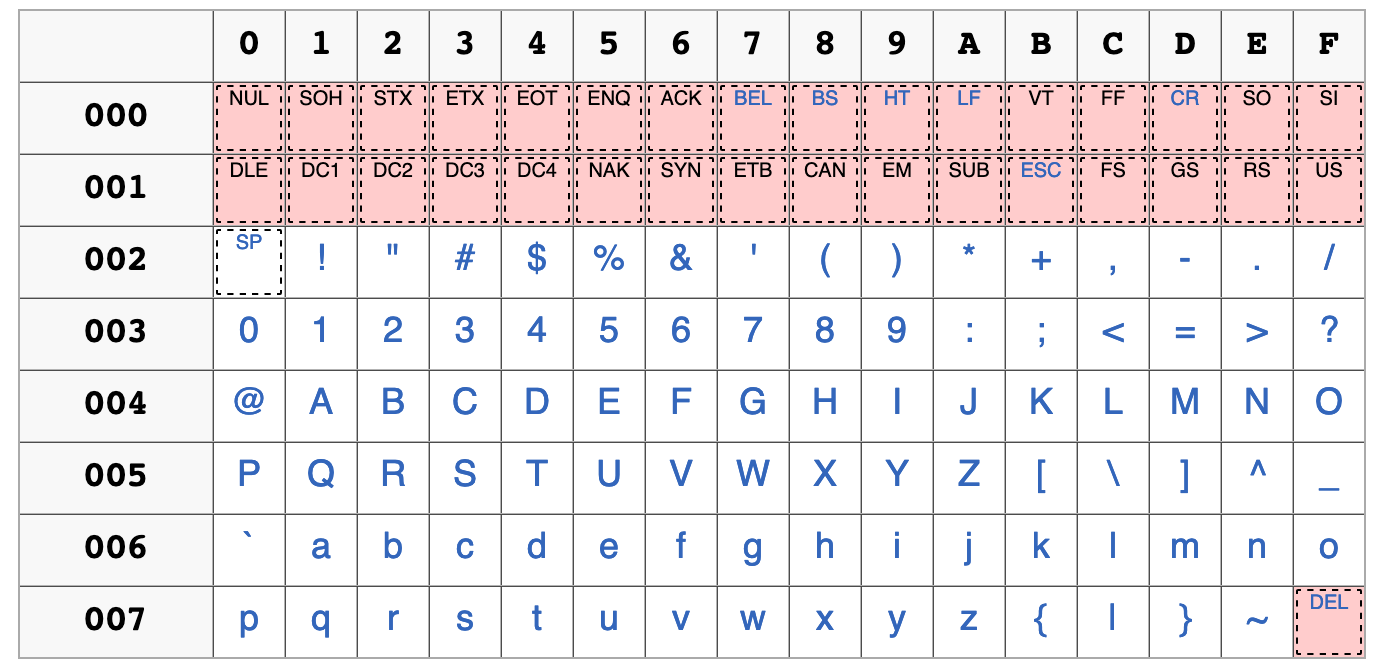
Cette table est à double entrée. La colonne de gauche représente les trois premiers chiffres hexadécimaux et la première ligne le dernier chiffre hexadécimal du codage du caractère.
On lit la table de la façon suivante:
on repère le caractère dans la table situé à l’intersection d’une ligne et d’une colonne;
sur la ligne de ce caractère, on note les trois chiffres hexadécimaux de la première colonne;
sur la colonne de ce caratère, on note le chiffre hexadécimal de la première ligne.
on concatène les trois chiffres de la première colonne avec le chiffre de la première ligne.
Exemple
La lettre capitale A est située sur la ligne contenant les chiffres \(004\) (première colonne) et sur la colonne contenant le chiffre \(1\) (première ligne). Donc le caractère A est représenté par la valeur hexadécimale 0041. Il est codé en binaire dans la machine comme sa représentation soit \(0100 0001\).
Norme ISO-8859#
Les caractères imprimables de la table ASCII sont devenus rapidement insuffisants pour transmettre des textes dans d’autres langues que l’anglais.
La table ASCII ne contient aucun caractère accentué ! Pour remédier à ce problème l’ISO, Organisme International de Normalisation a proposé la table ISO 8859 qui utilise 256 caractères sur un octet complet.
Pour définir le plus de caractères possible, la norme ISO définit plusieurs tables 8859-n où n est le numéro de la table. Il y a 16 tables pour les différentes langues.
En France, on a utilisé la table 8859-1, appelée aussi latin-1 et considérée comme multi-langue et la table ISO-8859-15 qui introduit le symbole monétaire € et qui gère mieux le français.
Tables de caractères ISO 8859-1 et 8859-15
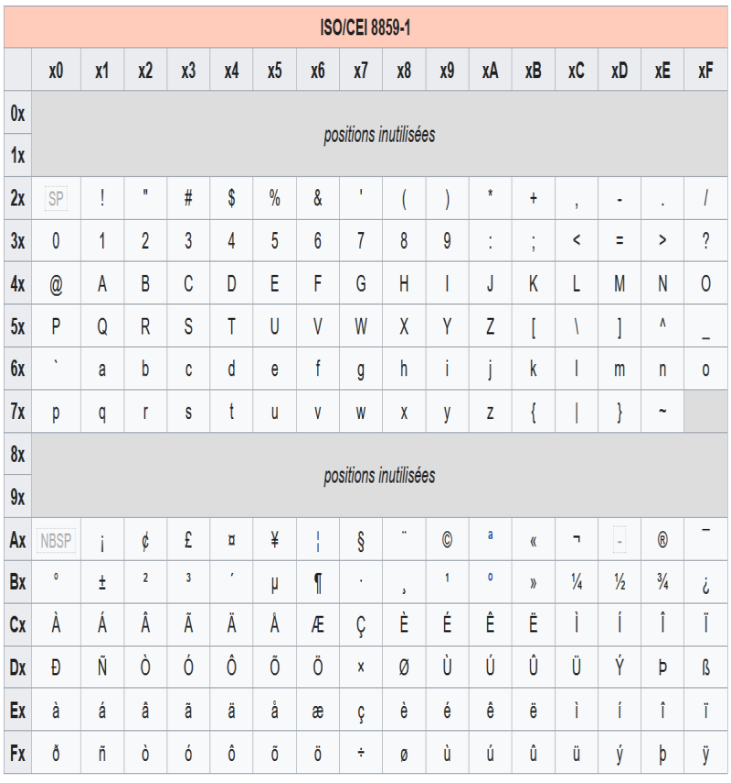
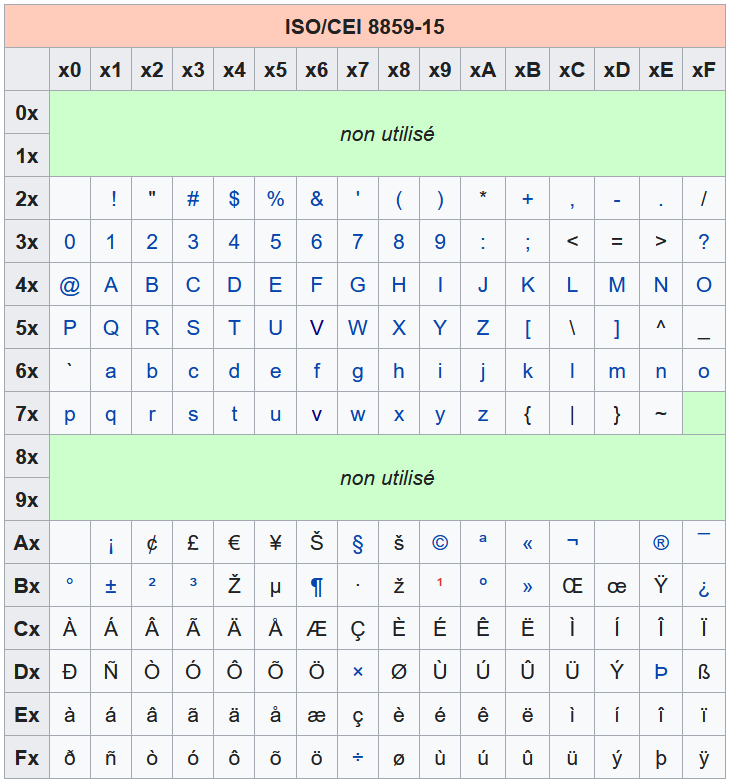
Les tables précédentes montrent que les 128 premiers caractères sont ceux de la table ASCII. Finalement, on a complété la table ASCII avec 128 nouveaux caractères (selon les langues et pays).
On peut remarquer quelques différences entre les tables ISO 8859-1 et ISO 8859-15 comme les fractions 1/4 et 1/2 peu utilisées en France et remplacées par les caractères collés comme OE et oe.
La norme Unicode#
La norme ISO 8859 permet d’encoder un grand nombre de caractères mais cela ne suffisait toujours pas. La multiplicité des tables rend difficile la rédaction d’un texte en plusieurs langues qui utilisent différentes tables ! Par exemple écrire un texte mélangeant le japonais et le français.
L’ISO a donc défini un jeu universel de caractères sous la norme ISO 10646 appelée UNICODE.
Cette norme associe à chaque caractère (lettre, idéogramme, emoji,…) un point de code. Ce point de code est un numéro en hexadécimal préfixé par U+.
Exemple
Le caractère “A” a pour point de code U+0041 et nom unique LATIN CAPITAL LETTER A. On remarque que c’est sa valeur hexadécimale dans la table ASCII.
Unicode est une norme qui définit les techniques pour encoder en binaire les points de code de façon plus ou moins économique. Ces encodages sont appelés Universal Transform Format et notés UTF-n où n désigne le nombre minimal de bits pour représenter un point de code (n=8, 16 ou 32).
UTF-8 est le format d’encodage qui utilise au minimum 8 bits (1 octet) pour encoder les caractères. Il est compatible avec la table de caractères ASCII. Les 128 premiers points de code sont ceux de la table ASCII.
Selon les caractères et la valeur des points de code, l’encodage en UTF-8 utilise 1, 2, 3 ou 4 octets.
Le tableau ci-dessous donne l’encodage des caratères en UTF-8.
Exemple
Le caractère accentué É que l’on retrouve dans la table ISO 8859-15 a pour point de code U+00C9. Ce point de code appartient à la plage \([U+0080; U+07FF]\) donc il est encodé en UTF-8 sur 2 octets (contrairement à l’encodage ISO qui n’en utilise qu’un seul).
Comment est-il encodé en binaire ?
L’encodage binaire sera de la forme \(110xxxxx~~10xxxxxx\) ou chaque x représente un bit issu du point de code.
On convertit en binaire \(00C9_{16} = 0000~0000~~1100~1001_{2}\) et on remplace chaque bit x par un bit de C9.
Sur 2 octets |
1 |
1 |
0 |
x |
x |
x |
x |
x |
1 |
0 |
x |
x |
x |
x |
x |
x |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
U+00C9 |
0 |
0 |
0 |
1 |
1 |
0 |
0 |
1 |
0 |
0 |
1 |
|||||
UTF-8 |
1 |
1 |
0 |
0 |
0 |
0 |
1 |
1 |
1 |
0 |
0 |
0 |
1 |
0 |
0 |
1 |
En écriture hexadécimale, le caractère de point de code U+00C9 est encodé en UTF-8 par C3 89.
En Python#
En python, on peut déclarer, sous réserve de coder en UTF-8, directement un caractère par son point de code unicode.
Par exemple pour le symbole � : c=\uFFFD.
Il existe une méthode encode() qui donne le codage binaire noté en hexadécimal d’un caratère dont on connait le point de code:
Avec c=\uFFFD et en exécutant c.encode(), cela renvoie b'\xe2\x82\xac' qui est le code hexadécimal de l’encodage en UTF-8 du caractère.